

AYSTORY
algo_lec20 본문
Example 2: Subset sum problem
- 가정:
𝑤₁ ≤ 𝑤₂ ≤ ⋯ ≤ 𝑤ₙ (입력 집합이 오름차순으로 정렬되어 있다고 가정함) - 정렬 이유:
원소들이 비감소(non-decreasing) 순서로 정렬되어 있으면 문제를 더 쉽게 해결할 수 있음. - 정의:
wsum은 현재 선택된 부분집합의 원소들의 합
조건 1: wsum == M인 경우
→ 현재 노드를 해(solution)에 추가하고
더 이상 추가할 수 있는 노드가 없으면, 해를 출력한 후 백트래킹
조건 2: 다음 원소를 선택할 경우,
wsum + w[i+1] > M이면
→ 더하면 목표값 M을 초과하므로 탐색 중지(stop)
- 정의:
rsum은 아직 탐색하지 않은 남은 원소들의 합 - 계산식: rsum=∑ (k=i+1 to n) w_k
조건 3: wsum + rsum < M이면
→ 앞으로 어떤 선택을 해도 M에 도달할 수 없으므로 탐색 중지(stop)
- 슈도코드
- Input: n positive integers 𝑤1, 𝑤2, … , 𝑤𝑛, subset sum 𝑀
- Output: Mark with 0 or 1 in the solution for 𝑋 = (𝑥1, 𝑥2, … , 𝑥𝑛)
sum_of_subsets(i, wsum, rsum) {
if (is_expand(i)) { // 확장 가능한지 확인
if (wsum == M) { // 해를 찾은 경우
print solution (nodes)
} else {
// i+1 번째 원소 선택한 경우
sum_of_subsets(i+1, wsum + w[i+1], rsum - w[i+1]);
// i+1 번째 원소 선택하지 않은 경우
sum_of_subsets(i+1, wsum, rsum - w[i+1]);
}
}
}is_expand(i) {
return ((wsum + rsum >= M) &&
((wsum == M) || (wsum + w[i+1] <= M)));
}Example 5: Traveling Salesman Problem with LC B&B
문제: TSP(외판원 문제)에서 현재까지 선택된 경로가 1→5일 때,
이 노드의 하한(lower bound) 을 계산하여 더 이상 유망하지 않은 서브트리를 잘라내는
LC B&B(Least-Cost Branch & Bound) 기법을 적용한다.

1. 현재 경로 비용
- [1]에서 [1,5]로의 이동 비용 c1,5=20
2. 남은 첫 이동 최소값
- 아직 돌아갈 곳이 남아 있는 정점 에서 다음으로 출발할 때 가능한 간선들 {c5,1 / c5,2 / c5,4}={7,17,4} 중 최소인 4
- v₅에서 “다음으로 출발”할 때 고려하는 간선은 아직 방문하지 않은 도시들로 가는 간선들만.
지금 경로가 1→5이므로 1번과 5번은 이미 방문된 상태이고, 남은 도시는 {2, 3, 4}뿐.
- v₅에서 “다음으로 출발”할 때 고려하는 간선은 아직 방문하지 않은 도시들로 가는 간선들만.
3. 미방문 정점별 “최소 진출 비용”
- 정점 2의 남은 간선 중 최소 min{c2,1 / c2,3 / c2,4}=min{14,7,8}=7
- 정점 3의 남은 간선 중 최소 min{c3,1 / c3,2 / c3,4}=min{4,5,7}=4
- 정점 4의 남은 간선 중 최소 min{c4,1 / c4,2 / c4,3}=min{11,7,9}=7
∴20+4+7+4+7=42
v₅에서 “다음으로 출발”할 때는 현재까지 만든 경로(1→5)를 깨지 않고, 아직 방문하지 않은 도시에만 이동할 수 있기 때문에
(5→1)은 “바로 돌아가는” 링크라 아직 방문할 도시로 넘어가지 않으므로,
제외 남은 도시는 {2, 3, 4}이고, {c₅₂, c₅₃, c₅₄} = {7, 17, 4} 중 최솟값 4를 택함.
반면, 하한(bound) 계산을 위해 “아직 시작도 하지 않은 다른 미방문 정점”들의 최소 ‘진출’ 비용을 구할 때는,
그 정점이 가지게 될 임의의 첫 번째 간선(방문 순서 상 제약이 없기 때문)을 고려.
즉, 정점 2는 나중에 2→1(시작점)으로 돌아갈 수도 있고, 2→3·4로 갈 수도 있으므로,
{c₂₁, c₂₃, c₂₄} = {14, 7, 8} 중 7을 최소값으로 사.
정점 3, 4 역시 “시작점 또는 다른 미방문 도시”로 연결될 수 있는 모든 간선을 보고 그중 최소를 택함.
Review: Sorting Algorithm Complexity
- 삽입 정렬(insertion sort), 선택 정렬(selection sort), 버블 정렬(bubble sort)
이 세 알고리즘은 모두 제자리(in-place) 정렬이며, 최악 및 평균 시간 복잡도가 Θ(n^2).
따라서 매우 큰 입력에는 실용적이지 않음. - 비교 기반 정렬의 하한(lower bound)
키를 비교만으로 정렬하는 모든 알고리즘은 Θ(n^2)보다 빠를 수 없다는 것을 다음 장에서 증명. - local move 제약
“한 번의 비교로 인접 두 원소만 교환하거나(혹은 이동이 전혀 없거나)”하는 방식의 정렬은 삽입 정렬과 거의 같은 작업량이 필요. - 보조 공간(auxiliary space)
전부 상수 공간 O(1)을 사용.
- 키와 순열
정렬되지 않은 리스트의 key를 x1,x2,…,xn이라 할 때, 이들을 정렬된 위치로 보내는 순열 π가 존재.
즉, 1≤i≤n에 대해 π(i)가 xi의 올바른 위치이다. - 키 값 재매핑
키들을 1,2,…,n으로 다룰 수 있는 이유는 이들과 1…n 사이에 일대일 대응 Ψ가 존재하기 때문.
따라서 입력 리스트 (x1,x2,…,xn)는 순열 (π(1),π(2),…,π(n))과 동치. - 예시
(2,4,1,5,3)라는 리스트가 있으면, π(1)=2, π(2)=4, π(3)=1, π(4)=5, π(5)=3이며, 이는 “값 2는 1번째 위치로, 4는 2번째 위치로, …”를 의미. - 역전(Inversion)의 정의
순열 π에서 역전 쌍은 i<j이면서 π(i)>π(j)인 (π(i),π(j))이다.
ex) (2,1), (4,1), (4,3), (5,3) 등
- 만약 어떤 정렬 알고리즘이 한 번의 비교로 최대 한 개의 inversion만 제거할 수 있다면,
임의의 순열 π를 정렬하기 위해 필요한 비교 횟수는 π의 역전 개수 이상이 되어야 한다.
즉, 역전의 개수가 곧 비교 횟수의 하한(lower bound)이 된다. - 한편, 역전의 최대 개수는 𝑛(𝑛−1)/2이며, 이는 입력이 완전히 내림차순 (n,n−1,…,1)일 때 발생한다.
- 따라서 최악의 경우, 모든 역전을 제거하려면 최소 n(n−1)/2회의 비교가 필요하며,
이로써 비교 기반 정렬 알고리즘의 시간 복잡도는 Ω(n²)임이 증명된다.
Review: Quick Sort with Stack
- Stack 기반 재귀 제거 Quick Sort
- 호출 최적화 방법: 작은 부분부터 먼저 정렬 → stack 깊이 O(log n)로 감소
Review: Insertion Sort
- 아이디어: 왼쪽은 정렬, 오른쪽은 미정렬. 오른쪽 원소를 왼쪽에 삽입
- 시간복잡도: 정렬된 경우 O(n), 역순일 경우 O(n²)
Insertion Sort vs Shell Sort
- Insertion sort
- Compare the current key to its predecessor
- Shell Sort
- 간격(gap)을 점차 줄이며 정렬. Use the "gap" for the comparison
- 삽입 정렬이 거의 정렬된 경우 빠르다는 점을 활용
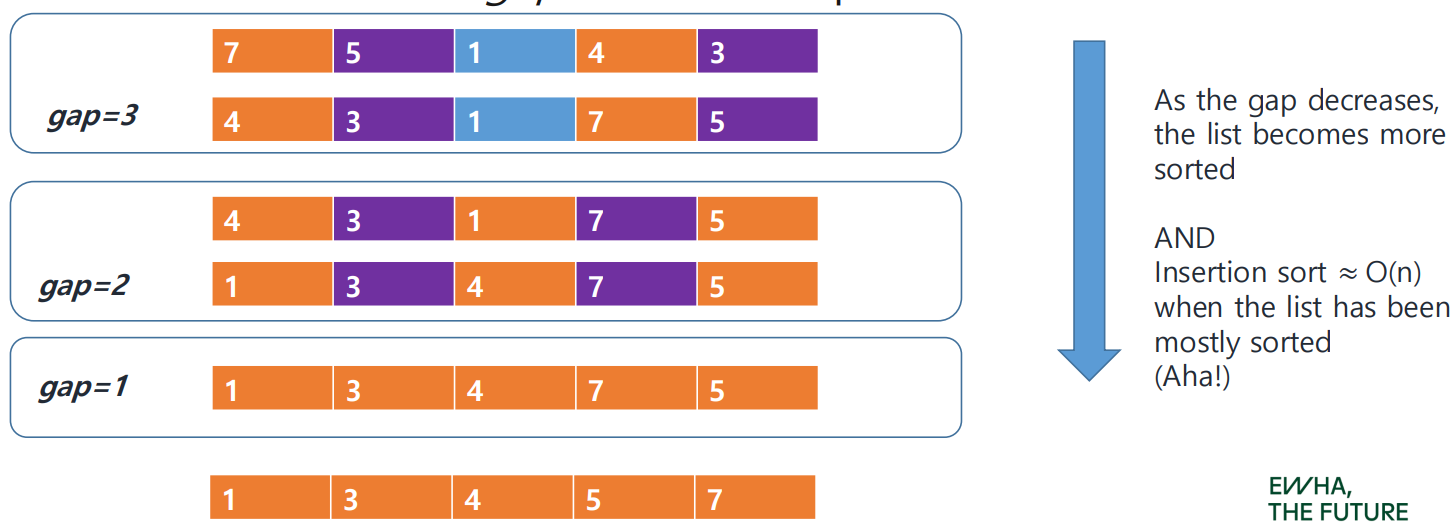
초기 리스트: 7 5 1 4 3
gap = 3 일 때 → 3칸 간격으로 나눈 서브리스트들을 삽입 정렬하면, 4 3 1 7 5
gap = 2 일 때 → 2칸 간격으로 나눈 서브리스트들을 삽입 정렬하면, 1 3 4 7 5
gap = 1 일 때 → 인접한 요소들만 비교하는 일반 삽입 정렬을 수행하면, 1 3 4 5 7
gap이 점점 줄어들수록 전체 리스트가 점차 정렬된 상태가 된다.
또한, 리스트가 이미 거의 정렬된 상태에서는 삽입 정렬의 시간 복잡도가 대략 O(n) 수준으로 가까워진다.
(아하! 이게 Shell sort의 핵심 idea)
Review Shel Sort
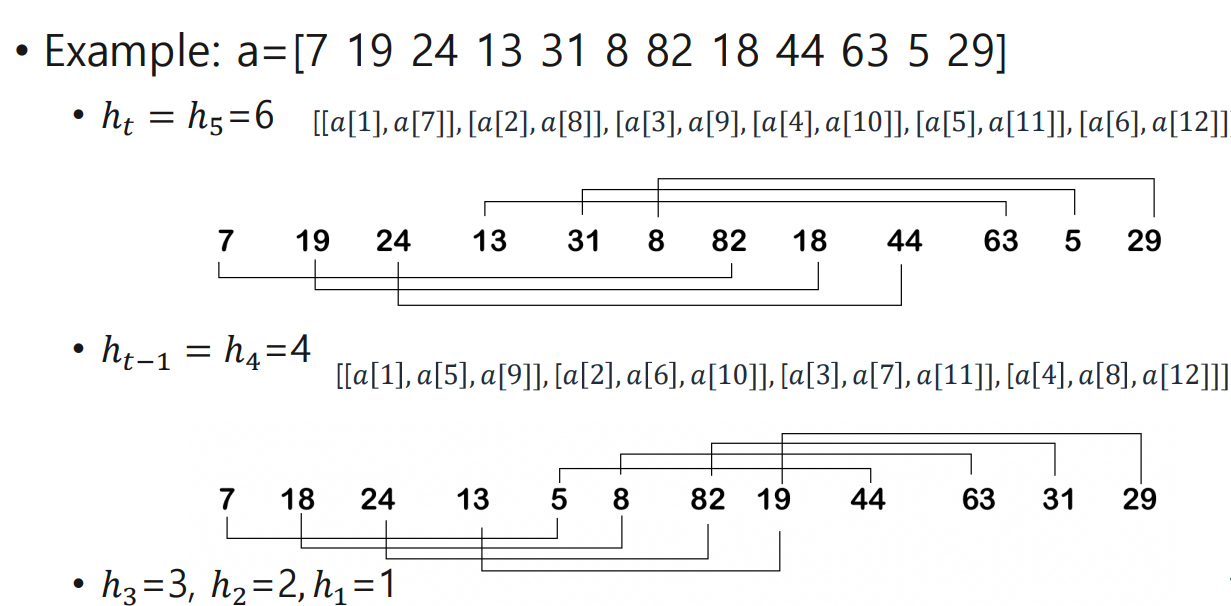
[문제 설명]
- 원본 배열
a = [ 7, 19, 24, 13, 31, 8, 82, 18, 44, 63, 5, 29 ]
인덱스 1 2 3 4 5 6 7 8 9 10 11 12
1) 첫 번째 gap: h₅ = 6
- 그룹: gap=6칸 떨어진 요소끼리 짝을 이뤄 삽입 정렬
- [a[1],a[7]] = [7, 82]
- [a[2],a[8]] = [19,18]
- [a[3],a[9]] = [24,44]
- [a[4],a[10]]=[13,63]
- [a[5],a[11]]=[31, 5]
- [a[6],a[12]]=[ 8,29]
- 각 짝을 삽입 정렬하면,
- [7,82] → [7,82]
- [19,18]→ [18,19]
- [24,44]→ [24,44]
- [13,63]→ [13,63]
- [31,5] → [5,31]
- [8,29] → [8,29]
- 이들을 다시 원래 위치에 배치하면, a = [ 7, 18, 24, 13, 5, 8, 82, 19, 44, 63, 31, 29 ]
2) 두 번째 gap: h₄ = 4
- 그룹: gap=4칸 떨어진 위치끼리 3개씩 묶어 삽입 정렬
- [a[1],a[5],a[9]] = [7, 5, 44]
- [a[2],a[6],a[10]] = [18, 8, 63]
- [a[3],a[7],a[11]] = [24,82,31]
- [a[4],a[8],a[12]] = [13,19,29]
- 각 그룹을 삽입 정렬하면,
- [7,5,44] → [5,7,44]
- [18,8,63] → [8,18,63]
- [24,82,31] → [24,31,82]
- [13,19,29] → [13,19,29]
- 배치 후 배열은 a = [ 5, 8, 24, 13, 7, 18, 31, 19, 44, 63, 82, 29 ]
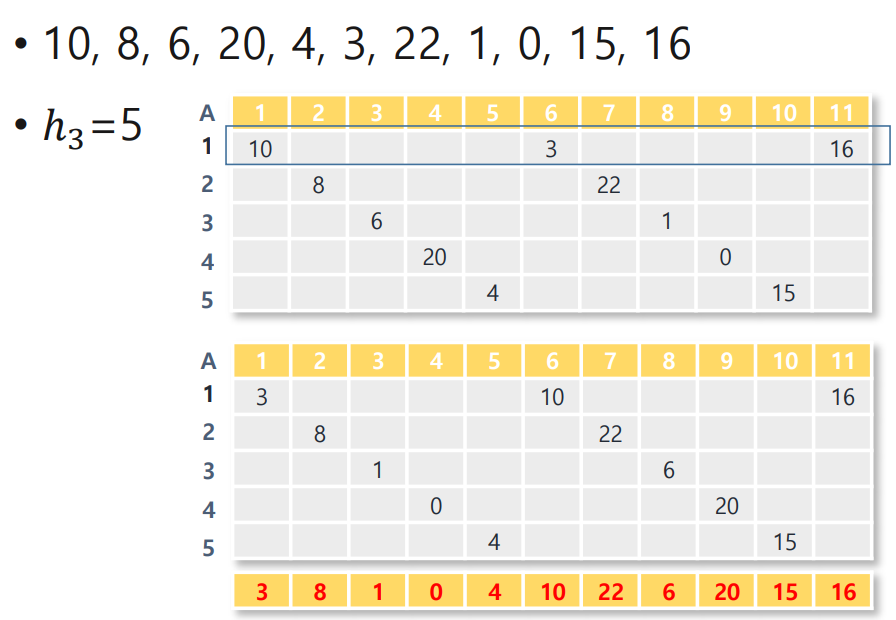
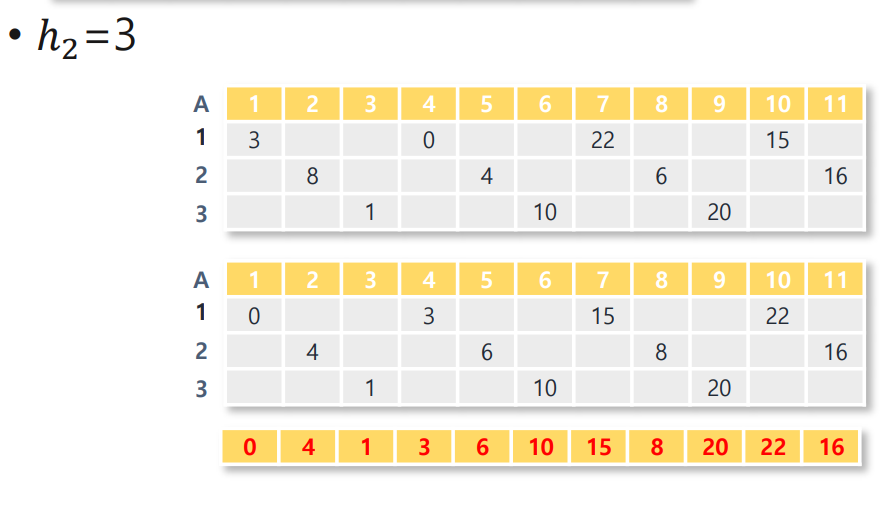
3) 다음 gap들: 3, 2, 1
- gap = 3 → 4개씩 묶어 삽입 정렬
- gap = 2 → 6개씩 묶어 삽입 정렬
- gap = 1 → 최종적으로 인접 요소끼리 삽입 정렬 (일반 Insertion Sort)
각 단계마다 “거칠게” 정리된 배열이 “점점 더 정교하게” 정렬되어 마지막에는 완전히 오름차순 정렬된 결과인
[1, 3, 5, 7, 8, 13, 18, 19, 24, 29, 31, 44, 63, 82] 로 수렴합니다.
- 간격이 점점 작아질수록 더 많은 요소들이 이미 정렬된 상태가 됩니다.
- 리스트가 이미 거의 정렬되어 있을 때, 삽입 정렬은 O(n) 번의 비교만으로 완료됩니다.
- 그럼 “서브리스트를 정렬할 때 어떤 알고리즘을 써야 할까?” 삽입 정렬을 사용합니다!
- 이유는
- 구현이 단순하다
- 모든 서브리스트를 관리하는 오버헤드가 거의 없다
- 서브리스트들이 거의 정렬된 상태라면 비교 횟수가 매우 적기 때문입니다.
- 이유는

Shell Sort에서 사용하는 gap(증분) 시퀀스 ht, ht−1, …, h1을 어떻게 고르면 가장 빠른지에 대한 연구 결과들을 정리
- 삽입 정렬 대비 성능
- Shell Sort의 최악 및 평균 수행 시간은
일반 삽입 정렬 Θ(n^2)보다 훨씬 빠릅니다.
- Shell Sort의 최악 및 평균 수행 시간은
- “최적” 증분(h) 시퀀스는 아직 미해결(open problem)
- 어떤 ht, ht−1, …, h1이 모든 n에 대해 최적의 성능을 보장할지는 아직 완전히 증명되지 않은 open problem.
- 주요 연구 결과
- t=2일 때, h≈1.72 * n^1/3 ⟹ 평균 수행 시간 Θ(n^5/3)
- 1≤k≤logn에 대해 hk = 2^k−1 ⟹ 최악 수행 시간 Θ(n^3/2)
- 실험적으로는 O(n^1.25)정도의 성능이 관찰됨.
- 가장 널리 알려진 최적의 증분 시퀀스(실무 구현에서 자주 사용하는 Ciura 수열):1, 4, 10, 23, 57, 132, 301, 701, …
요약:
Shell Sort는 적절한 증분 시퀀스를 이용해 삽입 정렬의 Θ(n^2) 병목을 대폭 개선하지만,
“어떤 시퀀스가 전반적으로 최적인가”는 아직 수학적으로 해결되지 않은 흥미로운 연구 과제로 남아 있습니다.
Review Heap Sort
- Max-Heap 구조
- Heap construction: O(n)
- Insert, delete Max: O(n log n)
- 구현 과정:
- 삽입, 삭제 시 swap과 shiftDown 연산 수행
- 최대 비교 횟수는 트리 높이에 비례
- Max-heap은 완전 이진 트리로, 각 노드의 값이 그 자식 노드들의 값보다 크거나 같다.
- 루트(root) 레벨을 0으로 잡을 때, 노드가 n개인 트리의 높이 h는 log2n.

- Insert x=45
- At beginning, put it at the last node
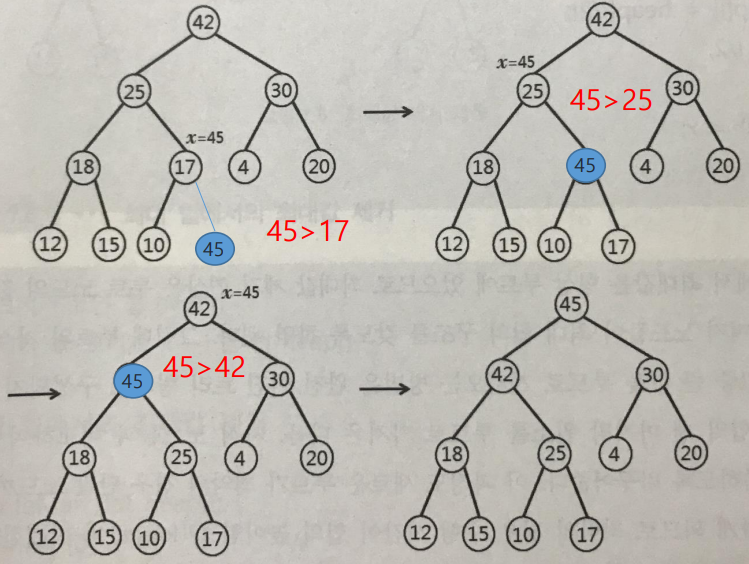
How many rearrangements (comparisons) does it make at maximum?
최대 몇 번의 재배열(비교)을 수행하나요?
- Delete MAX
- Swap root node and the last node

How many rearrangements (comparisons) does it make at maximum?
최대 몇 번의 재배열(비교)을 수행하나요?
- First step: construct initial max-heap
- Example: (6,3,8,2,7,1,9,4)

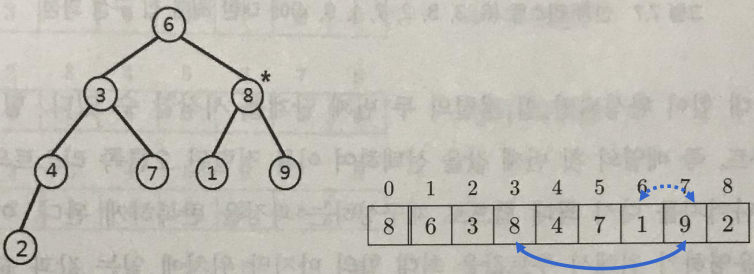

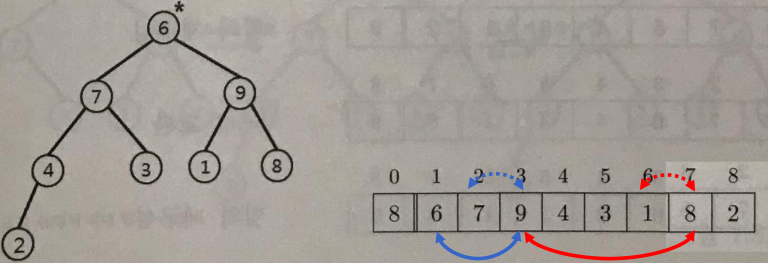

- Second step: Swap the root node and the last node, and re-construct max-heap



- 루트(최대값)와 마지막 원소 교환
- 현재 루트인 9와 배열의 마지막 원소(예: 4)를 swap.
- 힙 크기 축소
- 힙에서 마지막 원소(9)를 제외한 나머지 부분에 대해서만 다시 Max-Heap을 구성.
- Percolate-down
- 새로 루트에 올라온 값(4)을 자식과 비교해 필요한 만큼 아래로 내립니다.
- 이 과정을 n−1회 반복하면, 추출된 최대값들이 배열의 뒷부분에 오름차순으로 쌓이며 전체가 정렬.
- Time complexity
- First step
- At height i, max node count is 2^i and node count n will be 2^h <= n < 2^(h+1)
- h is tree height
- 레벨 i에 있는 노드에 대해 최대 i-1번의 원소 이동이 일어남. 즉, h-i번의 비교가 필요.
- 각 노드는 최대 2개의 자식노드를 갖고 있어서 즉 2(h-i)번의 비교가 필요. O(n)
- At height i, max node count is 2^i and node count n will be 2^h <= n < 2^(h+1)
- Second step
- From n nodes, keep switching the root node and the last leaf node
- Do reconstruct with the new root node: O(log2n)
- Reconstruction is executed n-1 times
- Thus, O(nlogn)
- First step

Bucket Sort
- 과정:
- 버킷 정의 Define buckets
- Scatter: 각 버킷에 값 분배
- 각 버킷 정렬 (삽입 정렬) Sort the entries in each bucket
- Gather: 버킷 순서대로 병합 Gather entries from each bucket

Example

1. Define buckets
- [1,5], [6,10], [11,15], [16,20], [21,25], [26,30]
주어진 키 값이 1부터 30까지라고 할 때, 이 범위를 같은 크기의 구간으로 나누는 과정입니다:
1. 전체 범위 결정
최소값 1, 최대값 30 → 길이 30
2. 버킷 크기(폭) 선택
여기서는 폭을 5로 정해서 30÷5=6개의 버킷을 만듭니다.
3. 버킷 구간 정의
버킷1: [1 … 5]
버킷2: [6 … 10]
버킷3: [11 … 15]
버킷4: [16 … 20]
버킷5: [21 … 25]
버킷6: [26 … 30]
4. 키 배분(Scatter)
각 키를 자신이 속한 구간의 버킷에 넣습니다.
예) 키 3 → 버킷1, 키 17 → 버킷4, 키 29 → 버킷6
5. 버킷별 정렬 및 합치기
- 각 버킷 안에서는 삽입 정렬 같은 간단한 알고리즘으로 정렬하고,
- 버킷1부터 순서대로 내용을 꺼내 합치면 최종 정렬 결과가 나옵니다.
2. Scatter
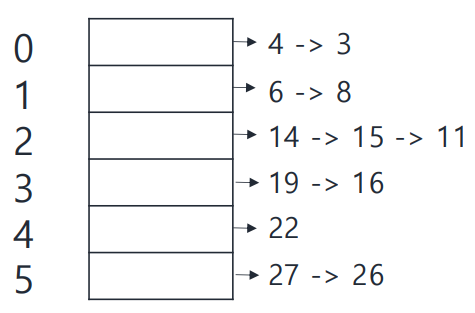
3. Sort the entries in each bucket

4. Gather entries from each bucket

일반적으로 키를 균등 분포에서 뽑는다고 가정하면,
- 평균 시간 복잡도 A(n) = O(n)
- Worst-case: 대부분의 키가 하나의 버킷에 몰려 있을 때
- n개의 항목이 전부 역순으로 하나의 버킷에 들어가 있고, 그 버킷 안에서 삽입 정렬을 사용하면 → O(n²)
- Best-case: 키가 균등하게 분포할 때
- n개의 항목이 n개의 버킷에 하나씩 들어 있을 때 → O(1)×n = O(n)
'Computer Algorithms' 카테고리의 다른 글
| algo_lec22 (0) | 2025.05.30 |
|---|---|
| algo_lec21 (1) | 2025.05.23 |
| algo_lec19 (1) | 2025.05.16 |
| algo_lec18 (0) | 2025.05.12 |
| algo_lec17 (0) | 2025.05.12 |



